

llama2-13b中文语言对话模型部署
前言
近期因工作需要调研了蛮多对话大模型,总结下来就目前来说,国内各种大模型开源的一般都是10B以下,表现都一般,不分语言的话排行榜也是长期被gpt、claude、llama2 70b占领。
中文排行榜目前体验下来感觉还是用llama2为基地模型再添加中文语料训练的效果比其他的效果好一点,当然这只是我个人体验,目前体验了清华和智谱的Chatglm2-6b和阿里的千问-7b,千问我用vllm还没跑通,用transformers又经常自我重复,网页demo还会乱码,体验欠佳。
除了国内大厂在做的工作之外,国外有个基于llama2做的工作叫OpenChat目前已经迭代到3.2的版本了,作者应该是个华人,体验了它的在线demo,效果已经可以媲美claude1了,非常牛逼,但我的消费级显卡4090没有跑通,显存不太够,到时候我试着量化看看尝试尝试。
但今天想介绍给大家的跟以上都没有关系,今天复现的是哈工大大佬崔一鸣博士的Chinese-llama2-Alpaca-13b的工作,也是近期开源。综合体验下来都还挺不错,工具也非常完善,回答质量能满足日常对话平均水平,代码的效果一般。
部署过程
项目支持很多部署工具

我这里详细介绍下Windows11平台下的llama.cpp的量化以及部署教程,其他的工具部署起来都比较简单。
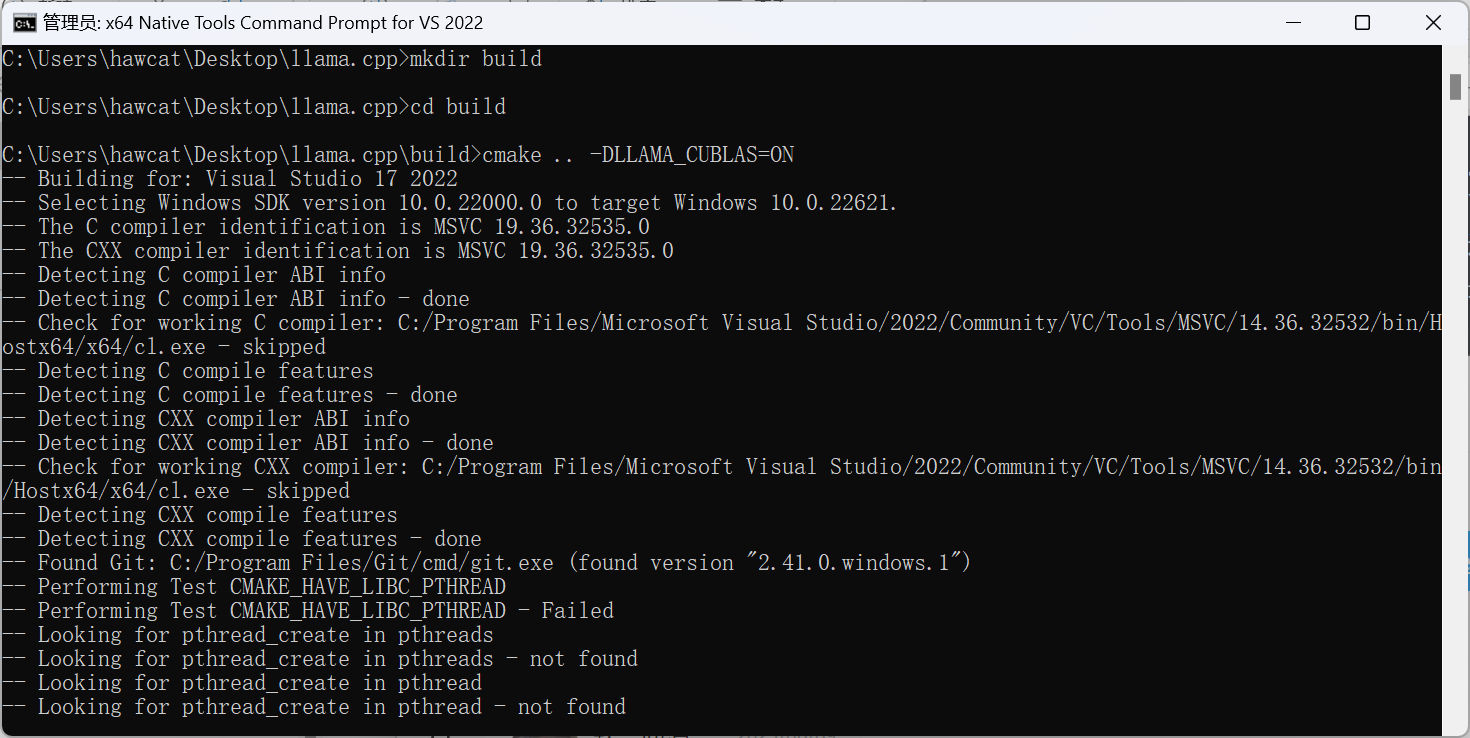
拉取llama.cpp并编译
这一步其实目前可以不用了,因为项目已经附带不同平台的编译版本。
1.拉取最新版llama.cpp仓库代码
使用Native Tools VS2022 或者本机有gcc或者g++工具包也行
1 | git clone https://github.com/ggerganov/llama.cpp |
2.开始编译 带GPU的建议与cuBLAS一起编译
1 | mkdir build |
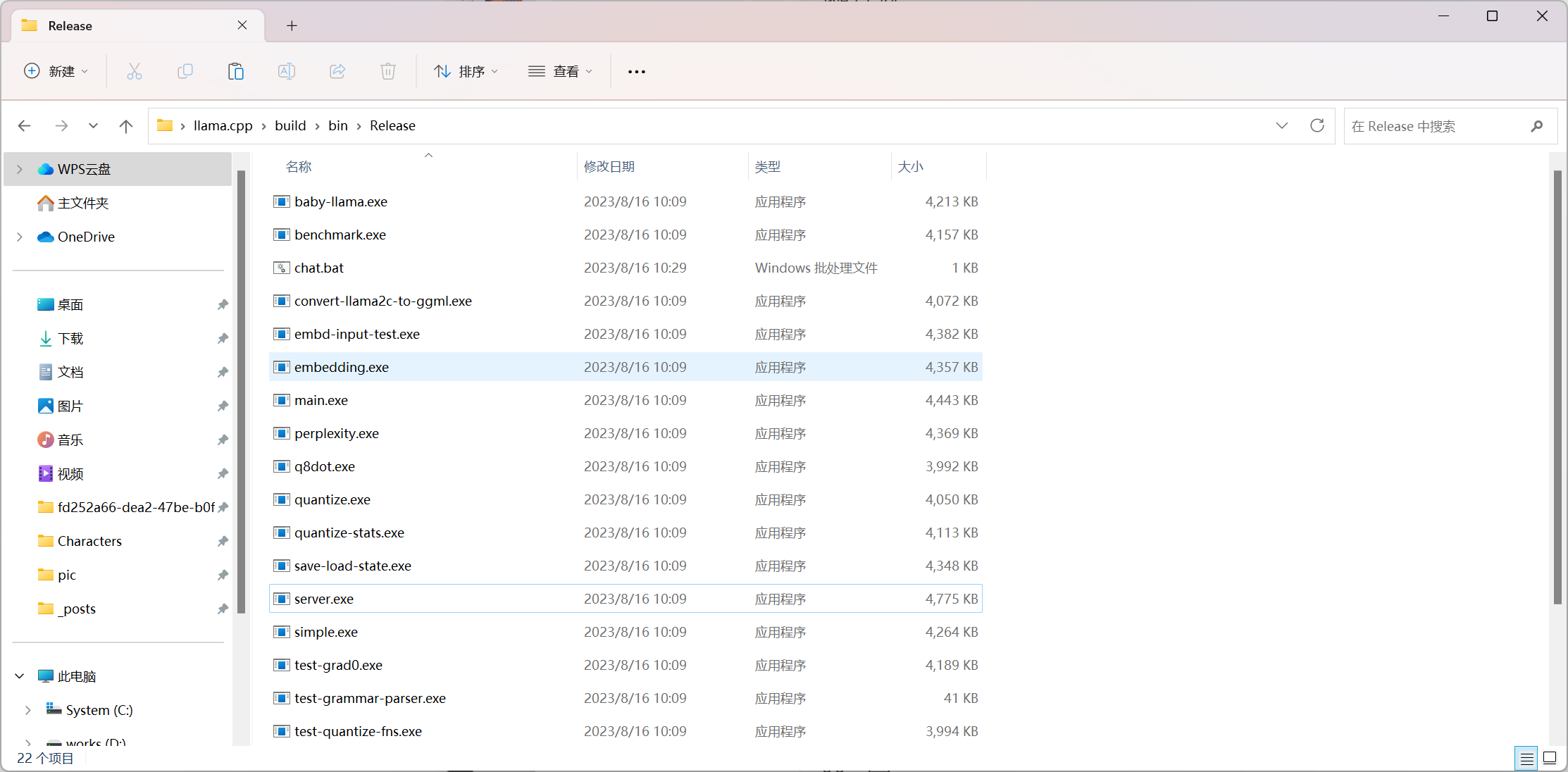
之后进入bin/release会带有编译好的版本
开始量化
1.第一步先把从huggingface上下载的pytorch.bin模型转换为fp16
1 | python convert.py zh-llama2-models/13B/ |
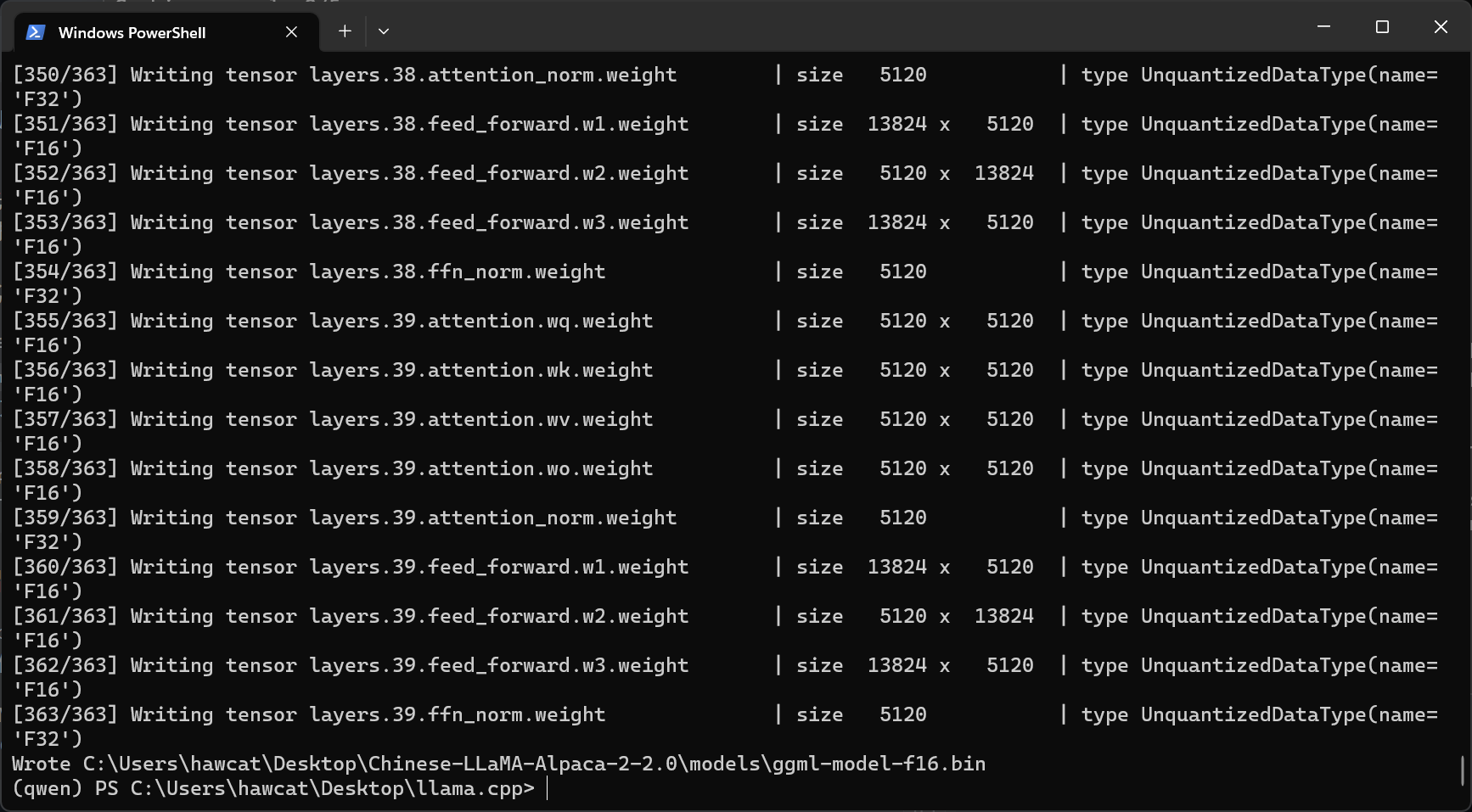
2.进入bin/release开始量化,我这里量化的版本是int4,目前来看效果蛮好,占用不高,回答生成速度也蛮快。
再用main测试:
1 | chmod +x chat.sh |
我这里改了一版bat的脚本,方便windows用户使用:
1 | @echo off |
可以加入GPU推理:通过Metal编译则只需在./main中指定-ngl 1;cuBLAS编译需要指定offload层数,例如-ngl 40表示offload 40层模型参数到GPU

对比
总的来说,从性能方面看,未量化版本的Llama-2-13b的GPU显存占用大约在18G左右,峰值在20G,量化过后的占用就比较少,集中在cpu上,包括存储占用也低了不少
llama2.cpp

webui未量化版本

希望能给您带来一些参考价值。