FastWAM 自采数据训练实验记录
1. 背景
最近尝试使用 FastWAM 训练自己的机器人抓取数据。
和 π0.5 / OpenPI 这类已经开放机器人基模的 VLA 不同,FastWAM 更像是:
视频生成基座 WanVideo
+ ActionDiT 动作模块
+ 自有机器人数据
→ 训练任务策略模型
也就是说,它没有重先验的预训练基模,而是借助视频世界模型的表征能力,来做训练。
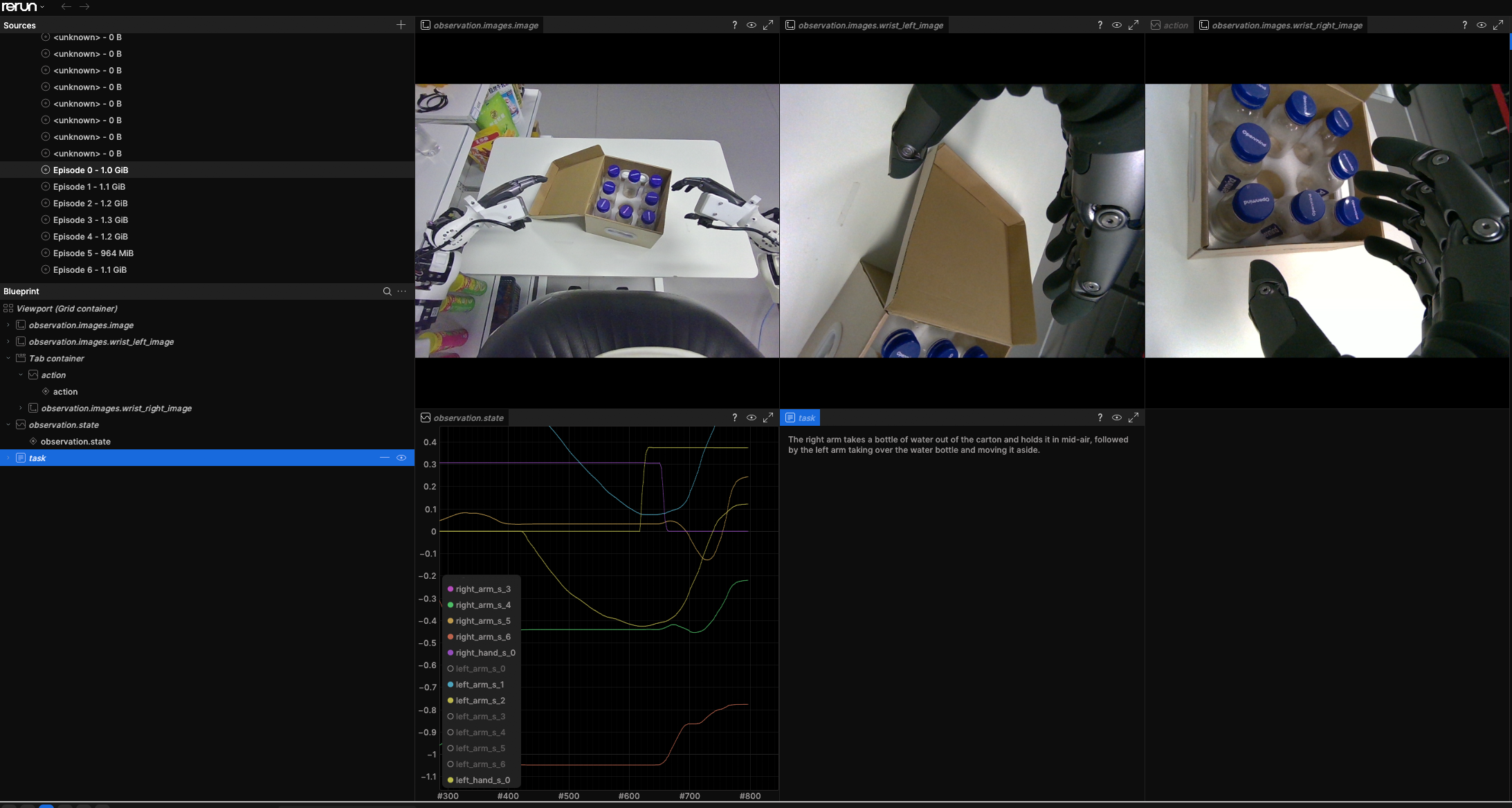
2. 数据准备
训练数据使用 LeRobot 格式,这一块我采用的是之前我们自采的数据,经过处理转换到v2.1的数据,目录大致如下:
dataset/
├── data/
│ └── chunk-000/
│ ├── episode_000000.parquet
│ └── ...
├── meta/
│ ├── tasks.jsonl
│ ├── episodes.jsonl
│ └── info.json
└── videos/
本次数据是三相机、双臂控制:
images:
- image
- wrist_left_image
- wrist_right_image
action:
shape: 16
state:
shape: 16
其中 16 维动作可以理解为:
右臂 7 + 右夹爪 1 + 左臂 7 + 左夹爪 1
需要特别注意:
1. action 和 state 的维度必须一致
2. 左右臂顺序必须固定
3. 相机 key 必须和配置一致
4. 动作和图像必须时间对齐
3. 模型地址配置
FastWAM 会加载 WanVideo 模型。配置里可以直接指定本地模型路径:
model:
model_id: /path/to/Wan-AI/Wan2.2-TI2V-5B
tokenizer_model_id: /path/to/Wan-AI/Wan2.2-TI2V-5B
redirect_common_files: false
如果使用 Hugging Face 下载,可以设置缓存路径:
export HF_HOME=/path/to/hf_cache
export HF_HUB_CACHE=/path/to/hf_cache/hub
如果代码走 ModelScope 下载,则 HF_HOME 不会生效,可以设置:
export MODELSCOPE_CACHE=/path/to/modelscope_cache
也可以给默认下载目录做软链接,避免大模型下载到项目目录里。
4. ActionDiT 预处理
FastWAM 需要预先生成 ActionDiT 初始化权重。
这里最容易踩坑的是 action_dim。
如果配置里写的是:
action_dim: ${data.train.processor.action_output_dim}
但预处理脚本只加载 model config,不加载完整 data config,就可能出现:
[WARN] action_dim is unresolved; defaulting to 7
如果自己的数据是 16 维动作,就必须显式写死:
proprio_dim: 16
video_dit_config:
action_dim: 16
action_dit_config:
action_dim: 16
然后重新生成:
python scripts/preprocess_action_dit_backbone.py \
--model-config configs/model/fastwam_uncond_preprocess.yaml \
--output /path/to/ActionDiT_uncond_16d.pt \
--device cuda \
--dtype bfloat16
如果从 joint 切换到 uncond,也建议重新生成一次 ActionDiT,避免结构或维度不一致。
5. 文本 Embedding 预计算
FastWAM 会从:
meta/tasks.jsonl
读取任务文本,并提前计算文本 embedding。
运行:
python scripts/precompute_text_embeds.py task=pick_bottle_3cam_384_1e-4

训练配置中需要指定缓存目录:
data:
train:
text_embedding_cache_dir: ./data/text_embeds_cache/pick_bottle
context_len: 128
如果是单任务训练,语言基本只是任务条件,不是训练中的主要矛盾。
6. 训练配置
核心配置大致如下:
batch_size: 2
gradient_accumulation_steps: 8
mixed_precision: bf16
learning_rate: 1.0e-4
lr_scheduler_type: cosine
num_epochs: 25
save_every: 2500
model:
_target_: fastwam.runtime.create_fastwam
proprio_dim: 16
load_text_encoder: false
action_dit_pretrained_path: /path/to/ActionDiT_uncond_16d.pt
这里使用的是 uncond 版本,也就是 FastWAM 默认路线:
不在推理时显式生成未来视频
直接根据图像、状态、语言条件预测 action chunk
相比 joint 和 idm,我个人推荐uncond 更适合先跑通训练和真机部署。
在作者的论文里面也详细介绍了三种训练模式在两个benchmark中的平均成功率
| 模式 | RoboTwin 平均成功率 | LIBERO 平均成功率 | 真实任务 | 推理速度 |
|---|---|---|---|---|
| uncond / Fast-WAM | 91.8% | 97.6% | 完成时间更好 | 190 ms,最快 |
| joint / Fast-WAM-Joint | 90.6% | 98.5% | 与其他 Fast-WAM 变体接近 | 比 uncond 慢 |
| idm / Fast-WAM-IDM | 91.3% | 98.0% | 成功率最高 | 810 ms,最慢 |
因为作者论文的数据都是在仿真数据里面测试的平均成功率,所以同时我也打算在我们自己本体的数据上做消融实验,对比joint、idm、uncond三种训练范式训练的模型效果真机对比。
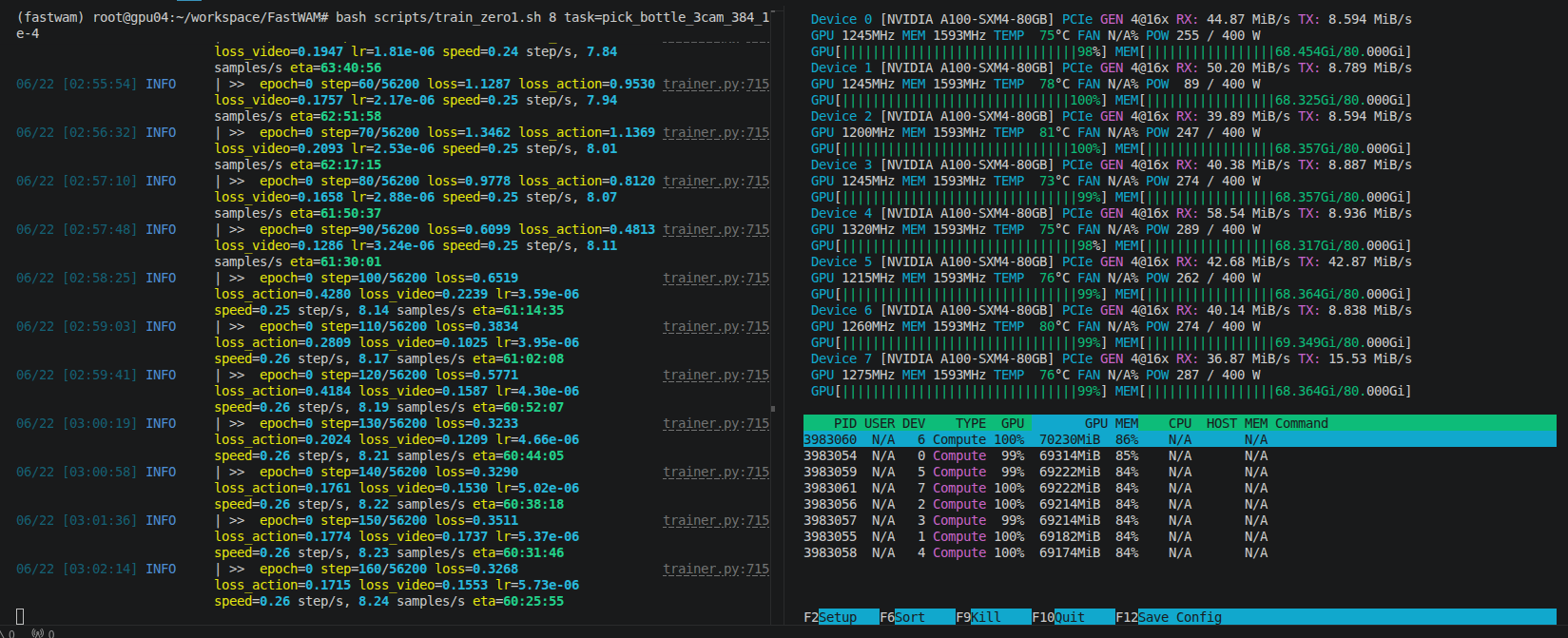
7. 显存问题
一开始使用下面这种配置很容易 OOM,特别是Zero-1的模型分布情况:
batch_size: 16
num_frames: 33
num_output_cameras: 3
video_size: [384, 320]
use_gradient_checkpointing: false
建议适当减小batch_size:
batch_size: 2
gradient_accumulation_steps: 8
model:
mot_checkpoint_mixed_attn: true
video_dit_config:
use_gradient_checkpointing: true
action_dit_config:
use_gradient_checkpointing: true
如果还是 OOM,可以继续降低:
batch_size: 1
gradient_accumulation_steps: 16
或者减少视频长度:
num_frames: 17
8. 训练指标
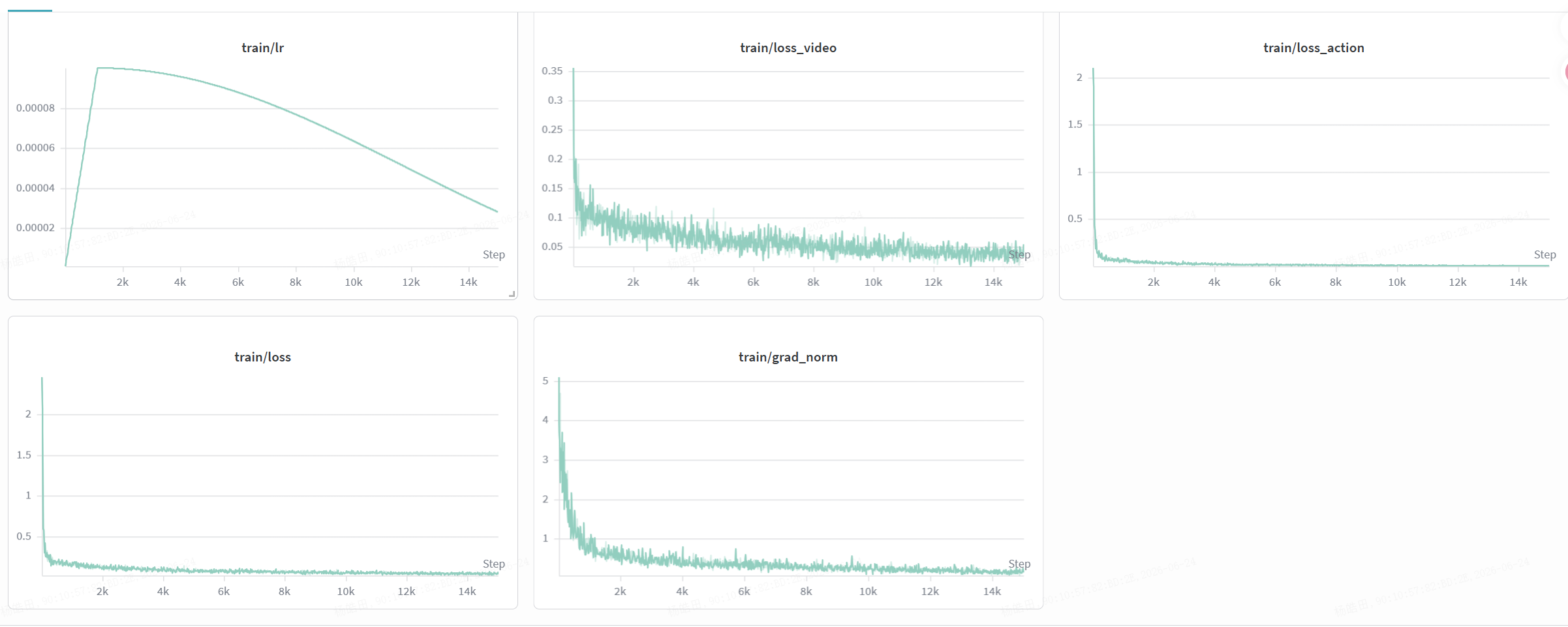
训练日志类似:
epoch=0 step=10/56200
loss=2.3737
loss_action=2.0108
loss_video=0.3629
lr=3.91e-07
speed=0.18 step/s
主要看这几个指标:
loss_action:动作预测损失,最重要
loss_video:视频/世界建模辅助损失
loss:两者总和
lr:学习率,前期 warmup 会很小
speed:训练速度
对于机器人控制,优先关注:loss_action
总结
FastWAM 使用自有数据训练时,重点不在语言,而在数据和动作定义。
对于少量自有数据,建议先做单任务、单场景 overfit,确认模型能学到动作,再逐步扩大数据规模和场景变化。
在模式选择上,建议优先使用 uncond / Fast-WAM 跑通完整链路。它训练时仍然保留视频世界建模的辅助监督,但推理时不显式生成未来视频,因此速度更快、结构更简单,也更适合真机部署和问题排查。
另外两种模式一个idm,推理时先预测未来视频,再生成action,另一个joint,联合视频token和动作token做action生成,都可以在我们自己的数据上做验证实验。
TODO:
- 不同训练范式的消融实验
- 真机部署效果对比
- 成功率统计